The second way to perform face swap is by an autoencoder neural network. Autoencoding is a data compression algorithm where the compression and decompression functions are data-specific, lossy (decompressed outputs will be degraded compared to the original inputs), and learned automatically.
We need three things to build an autoencoder: an encoding function, a decoding function, and a loss function (It measures the amount of information loss between the compressed representation of the data and the decompressed representations).
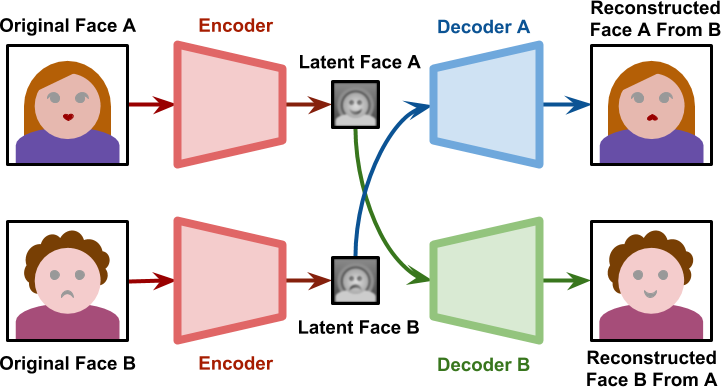
There is a very famous autoencoder model called Deepfakes which was used to exchange faces on videos. Its fame is due to the fact that the model was used for the edition of porn videos, swapping the original faces for faces of famous artists. It forces the two faces (source and target face) to be encoded on the same features by having both networks (an autoencoder for the source face and an autoencoder for the target face) sharing the same encoder, yet using two different decoders.
During the training phase, the both networks are treated separately. The decoder A is only trained with faces of A; the decoder B is only trained with faces of B. However, all faces are produced by the same Encoder. This means that the encoder itself has to identify common features in both faces.
The following image shows how DeepFakes works:
I was going to write about how to develop an architecture to perform face swap in the best way possible, but I found a blog post written by Alan Zucconi that explains all that very well, so I omit that part.